On attribue à chaque caractère un nombre entier (une chaîne binaire).
Il existe différents standards de codage.
Le nombre de caractères pouvant être codés dépend du standard choisi.
Les caractères à représenter sont :
-
d’une part, les caractères éditables (lettres majuscules et minuscules, chiffres, les signes mathématiques, les signes de ponctuation…),
-
d’autre part, les caractères non éditables (retour chariot…) ou commandes qui sont réservées à la réalisation de fonctions particulières par l’ordinateur (BEL, ACK…).
Le code ASCII (American Standard Code for Information Interchange)
Ce standard était à l’origine conçu pour l'alphabet anglais. Chacun des codes associés à un caractère est donné dans une table.
Exemple :
Le caractère A est codé en machine par la chaîne 010000012 soit 4116 et 65 en base 10.
Inconvénients :
-
Ce standard n’est pas adapté pour représenter des textes écrits dans d’autres langues, notamment celles qui utilisent des accents, des cédilles.
-
Il comporte peu de symboles : les caractères sont représentés sur un octet, le premier bit étant \(0\).
Autrement dit, à l'aide d'une chaîne de 8 bits : le premier bit étant \(0\), les 7 autres bits codant le caractère.
Ainsi, on ne peut coder que 128 (27) caractères.
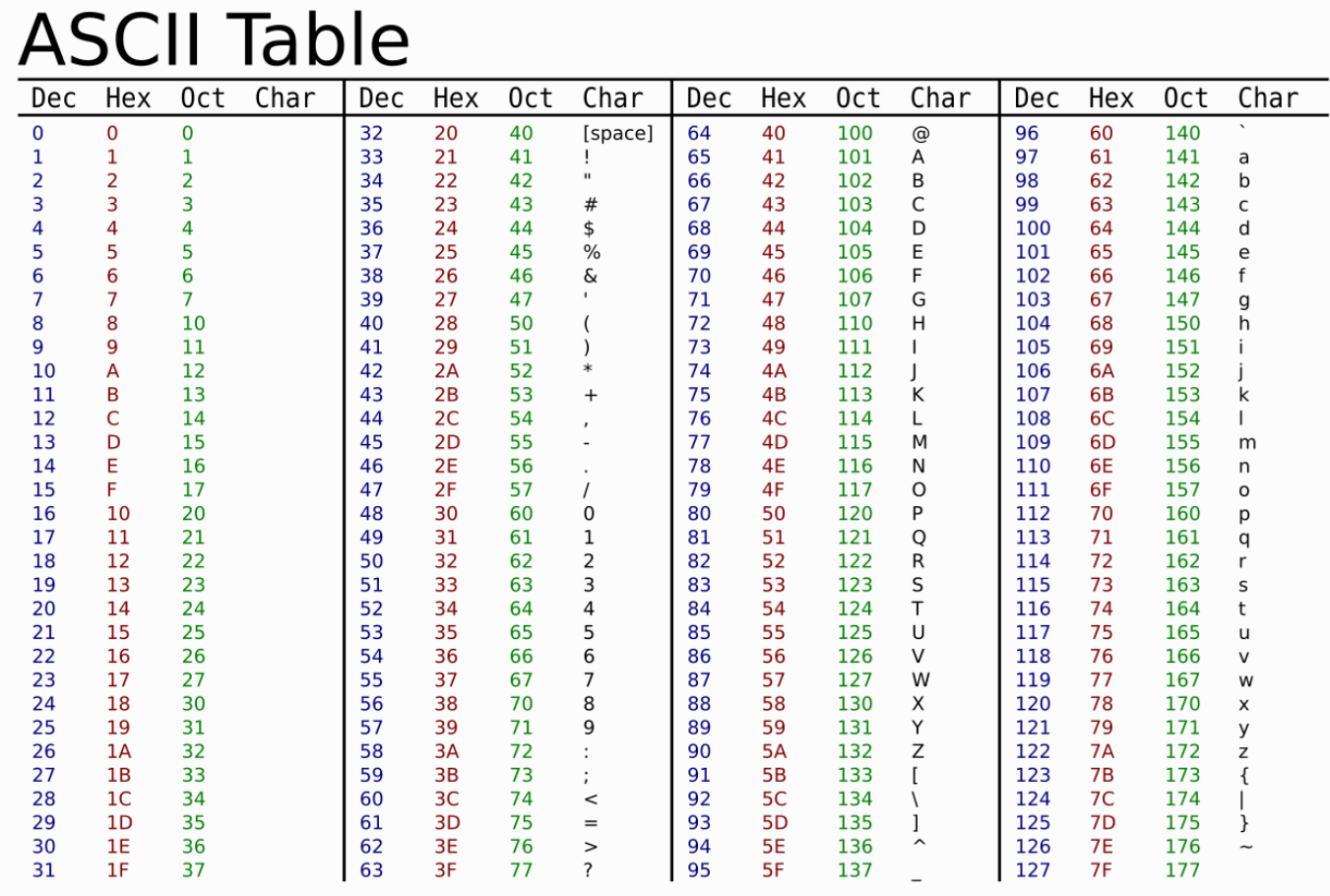
Afin de prendre en compte d'autres alphabets, l'Ascii a été progressivement étendu.
Les codes latin-1 (Europe occidentale ou norme ISO 8859-1) et latin-2 (Europe de l’Est).
Le standard latin-1 ajoute à l'Ascii les lettres « é », « É », « è », « ç », « æ », « ñ », « ö », etc. qui permettent de représenter les textes écrits dans la plupart des langues d’Europe de l’Ouest.
Inconvénients :
- Il manque encore des lettres utilisées par les langues d’Europe de l’Est.
- Il comporte encore par ailleurs peu de symboles : les caractères sont représentés sur 8 bits.
D'où l'introduction du code latin-2.
Les conventions précédentes ont l’inconvénient de ne permettre la représentation que d’un nombre réduit de caractères.
Le standard Unicode : UTF (Universal character set Transformation Format)
Unicode (Universal code) a vocation à unifier et coder tous les symboles en usage dans le monde (quel que soit l’alphabet et quelle que soit la langue). Il reprend les principaux caractères ASCII en les étendant.
Il associe à tout caractère un nom et un nombre quels que soient la plate-forme informatique ou le logiciel utilisé.
Unicode existe en plusieurs formats (selon la longueur de la chaîne binaire choisie).
Dans la pratique, on utilise le plus souvent la version UTF8 qui a l’avantage d’être moins coûteuse en termes d’espace mémoire.
Quant à l'Ascii, il a également été étendu pour intégrer les autres alphabets. La table Ascii étendue
Le système de codage natif de Python (et de la plupart des langages) est UTF-8. Ce codage des caractères coïncide avec l'ASCII pour les 128 premiers caractères. Les autres caractères sont représentés par plusieurs octets.
Faites-vous plaisir 1 :
- À quels caractères correspondent les codes ASCII suivants :
-
Trouver la représentation binaire en ASCII du texte : « Ainsi parlait Zarathoustra »
-
Trouver la représentation binaire en UTF8 du texte : « Le méchant est un ignorant. »
Faites-vous plaisir 2 :
Trouver le texte représenté en ASCII binaire par la suite de bits ci-après :
0100101001100101001000000111000001100101011011100111001101100101001000000110010001101111
0110111001100011001000000110101001100101001000000111001101110101011010010111001100101110
Faites-vous plaisir 3 :
À quoi servent, en Python, les commandes ord et chr ?