1. Qu'est-ce qu'un logiciel libre ?
1.1. Définition
« Logiciel libre » (free software) selon la Free Software Foundation désigne un logiciel qui respecte la liberté des utilisateurs.
Autrement dit, les utilisateurs ont la liberté d'exécuter, copier, distribuer, étudier, modifier et améliorer ces logiciels.
Exemples d'OS libres : Linux (et ses différentes distributions), Android, Unix.
Par ailleurs, il ne faut pas confondre logiciel libre et logiciel Open source qui sont deux philosophies différentes. Cependant, presque tous les programmes open source sont en fait libres.
« Les logiciels open source sont des logiciels pour lesquels le code est librement et publiquement disponible. »
Un logiciel non libre est dit propriétaire (on dit aussi de façon péjorative privateur ou privatif).
Les logiciels propriétaires sont essentiellement développés et mis à jour par l’entreprise qui les possède et qui peut décider d’arrêter de les maintenir. Ils sont très souvent payants.
Exemples d'OS propriétaires : Windows, MacOS, Android de Google.
Système d'exploitation Linux kernel.org
1. Présentation
Linux (on dit aussi GNU-Linux) est un système d'exploitation libre inspiré d'Unix et dont l'interpréteur de commande est appelé le Shell.
Ce dernier est accessible depuis une console, que l’on appelle aussi un terminal.
L'interpréteur par défaut de Linux est appelé le Shell-Bash.
L'utilisateur dispose de nombreuses commandes.
L'exécution des commandes s'inscrit, pour chaque utilisateur, dans le cadre d'une session de travail.
La session de travail est ouverte après que l'utilisateur s'est connecté au système, en fournissant à celui-ci son identifiant (le login) et son mot de passe. La session se termine lorsque l'utilisateur se déconnecte.
Un répertoire (aussi appelé dossier) est un ensemble de fichiers de l'ordinateur.
Le shell est en permanence associé au répertoire de l'usager en cours. Ce répertoire est appelé répertoire courant.
La prise en charge des commandes au cours d'une session est assurée par le shell qui est démarré par le système au début de la session. Cet outil attend les commandes de l'utilisateur pour les exécuter, cette attente étant matérialisée par un caractère spécial ($, #, ou >) appelé le prompt ou l'invite de commande.
-
Pour un utilisateur ordinaire, ce prompt est égal au caractère « $ ».
-
Pour le super utilisateur c'est-à-dire « root (\) », ce prompt est égal au caractère « # ».
On commence à taper la commande après le prompt.
-
Une commande peut contenir plusieurs lignes, le prompt est alors égal au caractère « > ».
2. La Syntaxe des commandes
Une commande est constituée par des mots séparés par des espaces
nom_de_la_commande [option1] [option2] ... arg1 arg2 ... argn
-
Une option est de la forme -x, avec x la lettre définissant l’option.
Une lettre étant peu explicite, il est souvent possible d’identifier une option via un ou plusieurs mots. Elle sera alors préfixée de --.
-
Un argument est une valeur.
Pour les noms de fichiers, il existe des caractères génériques qu'on appelle méta-caractères tels que :
- Le caractère * : il est interprété comme toute suite de caractères alphanumériques.
- Le caractère ? : il remplace un seul caractère alphanumérique.
- Les crochets remplacent un caractère choisi parmi ceux énumérés entre les crochets.
- Le tiret désigne un séparateur d'intervalle.
Linux existe sous différentes versions :
- Linux MINT ;
- Linux Ubuntu ;
- Linux Debian ;
- Kali-Linux
- etc.
3. Commandes de base sur les fichiers et les répertoires
Certaines commandes sur les fichiers sont informatives telles que : ls et cat
D’autres sont modificatrices telles que : touch, cp, mv, rm, less...
Certaines commandes sur les répertoires sont informatives telles que : pwd, cd.
D’autres sont modificatrices telles que mkdir et rmdir.
3.1. Système de fichiers
Les fichiers sont stockés sous la forme d’une structure hiérarchisée appelée arborescence.
Avec les systèmes de type Unix, le système de fichiers démarre à la racine, à la base de l’arborescence.
Il n’y a qu’une seule racine pour l’ensemble du système de fichiers.
La racine est notée par le caractère « / ».

Sous la racine, notée /, on trouve plusieurs répertoires (dossiers) :
-
des répertoires systèmes comme bin ou usr qui contiennent les commandes qu'utilise l'usager ;
-
des répertoires importants au bon fonctionnement de votre système d’exploitation comme etc car il contient les fichiers de configuration de votre système d’exploitation ;
-
des répertoires spécifiques comme tmp qui sert de stockage temporaire (au redémarrage de la machine, son contenu est supprimé) ;
-
le répertoire des utilisateurs home (aussi appelé home directory) qui contient le répertoire personnel de tout utilisateur de la machine.
Ainsi l’utilisateur Alice possède son propre répertoire appelé alice et situé dans /home.
3.2. Chemins d’accès dans l’arborescence
Le chemin d’accès est l’expression pour localiser un fichier ou un répertoire dans l’arborescence.
Il existe deux types de chemin d’accès.
3.2.1. Chemin absolu
Un chemin (d’accès) absolu sur le système de fichiers permet d’identifier sans ambiguïté un élément de l’arborescence, qu’il s’agisse d’un répertoire ou d’un fichier.
Exemple : Construction du chemin du fichier photo1.png de l’arborescence ci-dessus.
- Nom du fichier : photo1.png
- Première étape : Documents/photo1.png
- Deuxième étape : alice/Documents/photo1.png
- Troisième étape : home/alice/Documents/photo1.png
- Dernière étape : /home/alice/Documents/photo1.png
Le chemin d’accès /home/alice/Documents/photo1.png est dit absolu car il identifie sans ambiguïté le fichier photo1.png dans l’arborescence.
Tout chemin qui commence par la racine est un chemin absolu.
3.2.2. Chemin relatif
Les chemins qui ne commencent pas par la racine sont dits chemins relatifs. Leur signification est fonction du répertoire de départ appelé répertoire courant.
Attention ! Les chemins relatifs peuvent être ambigus.
Symboles spéciaux utilisés dans le chemin d’accès
| Symbole |
Signification |
| \(..\) |
Répertoire parent |
| \(/\) |
Sépare les branches dans un chemin |
| \(.\) |
Répertoire courant |
| ~ (tilde) |
Répertoire de base de l'usager |
Si le répertoire courant est le répertoire Documents de l’utilisateur alice, alors les chemins relatifs suivants font tous référence au même fichier désigné par le chemin absolu /home/alice/Documents/monfichier.txt :
- monfichier.txt
- ./monfichier.txt
- ..Documents/monfichier.txt
- ~/Documents/monfichier.txt
3.3. Parcourir le système de fichiers
Avant de réaliser toute action, il est nécessaire de savoir où l’on se situe dans l'arborescence, c’est-à-dire savoir quel est le répertoire courant.
La commande pwd (Print Working Directory) affiche le chemin d’accès absolu du répertoire courant.
Cette commande est informative, elle ne modifie pas le répertoire courant ni le système de fichiers.
Pour changer de répertoire courant et donc se déplacer dans l'arborescence, on utilise la commande cd (Change Directory).
La commande cd change le répertoire courant par le répertoire passé en argument, qu’il soit relatif ou absolu.
-
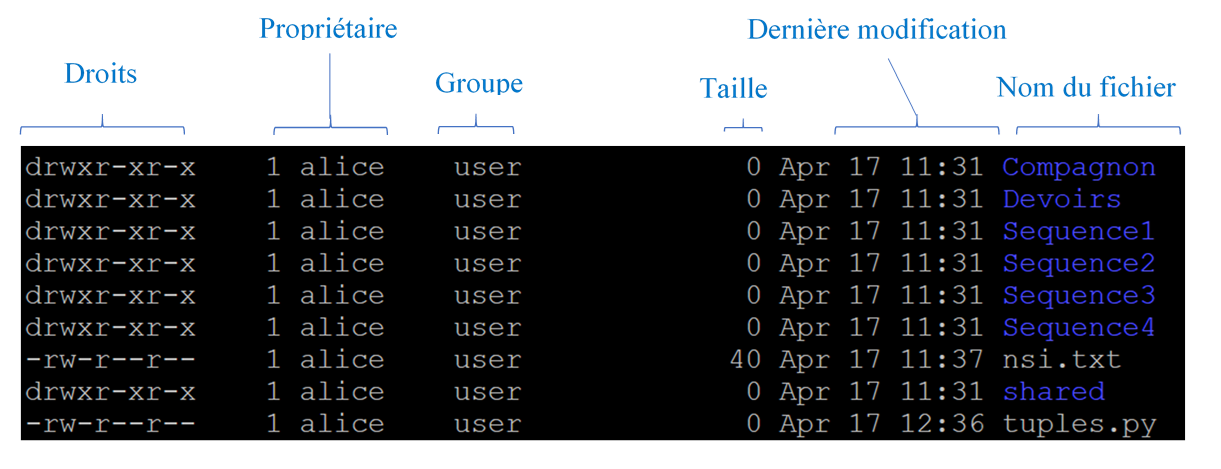
La commande ls (List Segments) avec ses options permet d'observer le contenu d'un répertoire.
ls -l affiche le contenu détaillé.
-
La commande less () permet d'afficher le contenu d'un fichier.
-
La commande cat (conCATenate) permet de concaténer des fichiers puis les afficher.
-
La commande nano () permet d'éditer (modifier) un fichier.
3.4. Les commandes de modification de l’arborescence
Sur les répertoires,
-
mkdir (MaKe DIRectory) permet de créer un répertoire.
-
rmdir (ReMove DIRectory) permet de supprimer un répertoire vide.
-
rm -r (ReMove) permet de supprimer un répertoire non vide.
-
mv (MoVe) permet de déplacer ou renommer un répertoire.
Sur les fichiers,
-
touch permet de créer un fichier vide.
-
rm permet de supprimer un fichier.
-
mv permet de renommer un fichier ou déplacer un fichier vers un autre répertoire.
Attention ! Si vous renommez un fichier et choisissez un nom qui existe déjà, le fichier précédent sera écrasé par le fichier que vous déplacez. Il n'y a aucun moyen de récupérer le fichier précédent si vous l'écrasez accidentellement.
-
cp (CoPy) permet de dupliquer un fichier.
-
La commande > permet de rediriger la sortie vers le fichier indiqué.
date > monfichier
La commande >> fonctionne comme la commande >, mais si le fichier cible existe déjà, on ajoute le texte à la suite.
3.5. Demander de l'aide
-
La commande man (manuel) permet de demander de l'aide sur l'usage d'une commande.
-
La commande whatis sert à accéder à un court résumé de l'usage d'une commande.
4. Droits des utilisateurs
Un système d’exploitation de type Unix est un système d’exploitation multi-tâches et multi-utilisateurs. Cela signifie que sur une même machine plusieurs personnes peuvent travailler simultanément.
Le système doit donc pouvoir gérer plusieurs utilisateurs en même temps en assurant à la fois le partage des ressources (espace disque, utilisation de la mémoire, périphériques. . .), la confidentialité des données de chaque utilisateur et bien sûr l’intégrité de l’arborescence des répertoires et des fichiers.
Puisque plusieurs personnes peuvent être connectées en même temps, le système doit pouvoir identifier clairement chacun des utilisateurs ainsi que les ressources auxquelles il a accès, et plus généralement qui a le droit de faire quoi.
Ainsi, chaque personne autorisée à utiliser un système de type Unix se voit attribuer un compte utilisateur et il existe un ensemble de règles qui régissent ce qu’elle a le droit de faire.
4.1. Identification des utilisateurs
4.1.1. Généralités
Il y a deux types d’utilisateurs
-
Un super-utilisateur qui a le droit de faire tout ce qu’il veut sur le système, absolument tout : créer des utilisateurs, leur accorder des droits, supprimer des utilisateurs, avoir accès à leurs données, modifier le système.
Ce super-utilisateur s’appelle root. C’est l’administrateur du système (celui qui a installé le système).
-
Et les usagers (autres utilisateurs) ordinaires.
Ceux-là n’ont qu’une possibilité d’action limitée et n’ont surtout pas la possibilité de modifier le système.
Ces utilisateurs peuvent être répartis dans différents groupes
4.1.2. Utilisateurs et groupes
Pour être identifié sur un système de type Unix, il faut posséder un compte utilisateur, créé par le super-utilisateur et caractérisé par un identifiant de compte et un mot de passe.
Pour se connecter sur le système par une console et ouvrir une session de travail, il faut entrer son identifiant à l’invite login puis son mot de passe à l’invite passwd.
Outre son identifiant de compte, chaque utilisateur est identifié par un numéro unique uid (User IDentifier) et appartient à un groupe principal gid (Group IDentifier) et éventuellement à des groupes secondaires d’utilisateurs.
-
Le groupe principal est utilisé par le système en relation avec les droits d’accès aux fichiers.
Chaque utilisateur doit appartenir à un groupe principal.
-
Les groupes secondaires sont les autres groupes auxquels un utilisateur appartient.
Pour connaître son uid et les groupes auxquels on appartient, on peut utiliser la commande id (IDentity).
4.2. Droits d'accès
Chaque utilisateur d’un système de type Unix se voit attribuer un identifiant de compte ainsi qu’un répertoire personnel rangé sous le répertoire /home. Ce répertoire personnel porte le nom de l’identifiant de compte de l’utilisateur et lui appartient. C’est dans ce répertoire qu’il va pouvoir stocker ses fichiers.
Les fichiers bénéficient d’une protection en lecture, écriture et exécution, c’est-à-dire qu’un utilisateur peut choisir que ses fichiers soient lisibles et/ou modifiables par d’autre utilisateurs et il peut empêcher ou autoriser que d’autres utilisateurs lancent ses propres programmes. C’est le principe des droits d’accès.
les droits d’accès sont définis suivant trois publics différents :
le propriétaire du fichier ;
les membres du groupe principal du propriétaire ;
les autres utilisateurs du système.
Pour chacun de ces publics, il existe 3 droits d’accès :
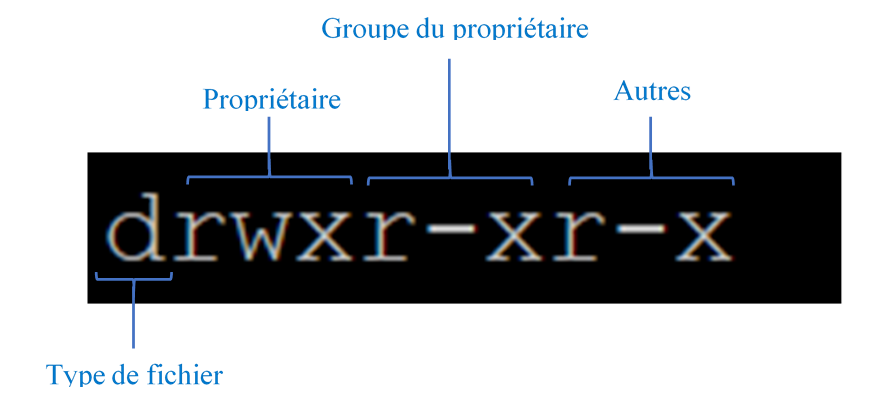
Exemple :
Le code rwxr-x--x signifie que
- le propriétaire peut lire, modifier (écrire) et exécuter le fichier,
- que les membres de son groupe peuvent le lire et l'exécuter, mais pas le modifier,
- et que les autres utilisateurs ne peuvent que l'exécuter.
4.3. Changer les droits des éléments du système de fichiers
La commande chmod (CHange MODe) permet de modifier les droits d’accès d’un fichier ou d’un répertoire.
Pour pouvoir l’utiliser, il faut être le propriétaire du fichier.
Syntaxe générale : chmod public opération droit où :
-
public peut prendre comme valeur
- u pour le propriétaire (user) ;
- g pour le groupe principal ;
-
o pour les autres utilisateurs (other) ou n’importe quelle combinaison de ces trois valeurs.
Il peut aussi prendre la valeur a (all) qui est équivalente à la combinaison ugo
-
opération est le caractère
- « + » pour ajouter le droit ;
- « - » pour le supprimer ;
- ou « = » pour affecter un droit.
-
droit peut prendre comme valeur r, w, x ou toute combinaison de ces trois valeurs.
Il existe une autre méthode, plus concise, mais moins intuitive de représenter les autorisations. Cette dernière utilise l'écriture octale.
En utilisant cette méthode, chacun des publics cibles est représenté par un nombre compris entre 0 et 7.
- \(1\), si l'accès est autorisé
- \(0\), sinon.
Ainsi,
| Droits |
Écriture binaire |
Écriture Octale |
| rwx |
\(111\) |
\(7\) |
| r-- |
\(100\) |
\(4\) |
Avec cette notation, les droits rwxr-xr-- sont équivalents, en base 8, à 754.
- Le propriétaire du fichier à tous les droits (soit 7) ;
- Les membres de son groupe peuvent lire et exécuter le fichier (soit 5) ;
- Les autres ne peuvent que lire le fichier (soit4)
.
La commande sudo (Switch User DO) permet à un utilisateur de prendre temporairement l’identité du super-utilisateur (root) afin d’exécuter une commande nécessitant ses droits d’accès. Il doit y être autorisé par le super-utilisateur (celui qui a installé le système)!

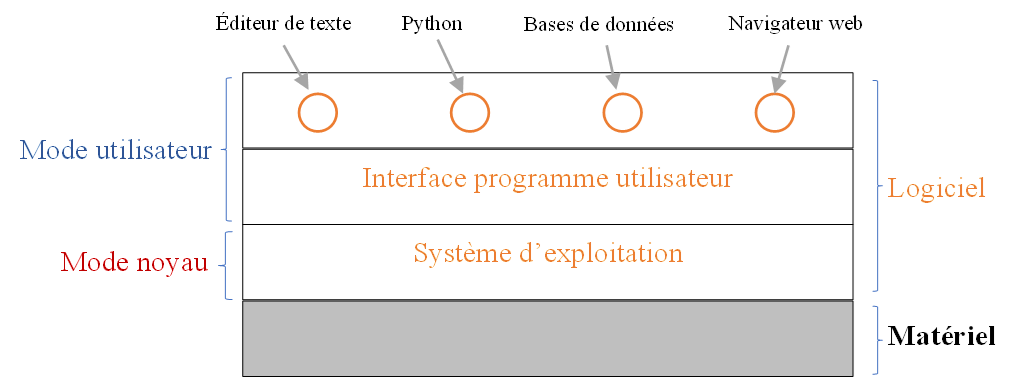 En résumé, un système d'exploitation a divers rôles :
En résumé, un système d'exploitation a divers rôles :