La toile ou plus précisément toile mondiale (World Wide Web, WWW en anglais) est un ensemble de fichiers interconnectés (textes, images...) via des liens hyperliens.
Une page peut contenir de nombreux liens hypertexte renvoyant à d'autres pages hébergées n'importe où dans le monde.
Les pages sont consultées au moyen d'un programme appelé navigateur (Firefox, Google, Qwant...). Le client (ici, un navigateur) récupère la page demandée auprès d'un programme appelé serveur, puis interprète le texte et les commandes de formatage (mise en forme) qu'elle contient et l'affiche correctement formatée.
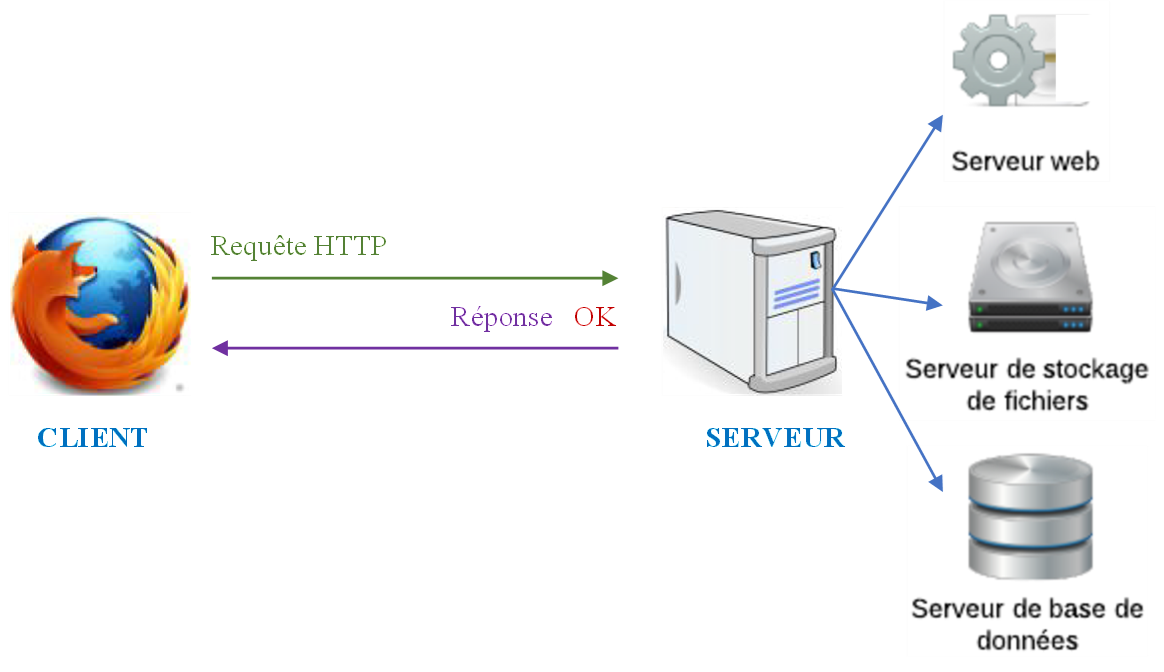
Il existe également une grande variété de serveurs en fonction des services à fournir :
Un serveur web est un ordinateur hébergeant (stockant) un ou plusieurs sites web. Il publie des pages Web demandées par des navigateurs Web
Un serveur de stockage de fichiers statiques permet de partager des fichiers sur un réseau.
Un serveur de base de données enregistre les informations de façon structurée. Il permet aux clients de transmettre ou récupérer des données.
Un serveur DHCP (Dynamic Host Configuration Protocol) fournit automatiquement des configurations réseau à des ordinateurs et d'autres périphériques au sein d'un réseau.
etc.
Architecture client-serveur
L'architecture client–serveur désigne un mode d'échange (souvent à travers un réseau) entre plusieurs programmes : l'un, qualifié de client et l'autre, qualifié de serveur.
Le client est l'interface utilisateur ou l'application qui demande des services ou des ressources au serveur.
Le serveur est un programme ou un système qui répond aux demandes du client. Il détient les ressources ou les données nécessaires pour fournir les services demandés par le client.
Par exemple, les serveurs Web attendent une requête du client Web (un navigateur web) puis la traitent quand elle arrive. Il répond ensuite au navigateur avec un message HTTP Response. La réponse contient un statut HTTP Response indiquant si, oui ou non, la requête a abouti.
Par extension, le client désigne souvent l'ordinateur sur lequel est exécuté le programme client, et le serveur, l'ordinateur sur lequel est exécuté le programme serveur.
Très souvent, des serveurs sont regroupés au sein d'une même machine physique.
Contrairement à l'architecture client-serveur, où il y a un serveur centralisé qui fournit des services aux clients, un réseau Peer-to-peer (P2P ou pair à pair) est une architecture de réseau informatique où chaque machine du réseau peut agir à la fois comme client et comme serveur en partageant des ressources avec d'autres machine du réseau.
Fonctionnement de la Toile
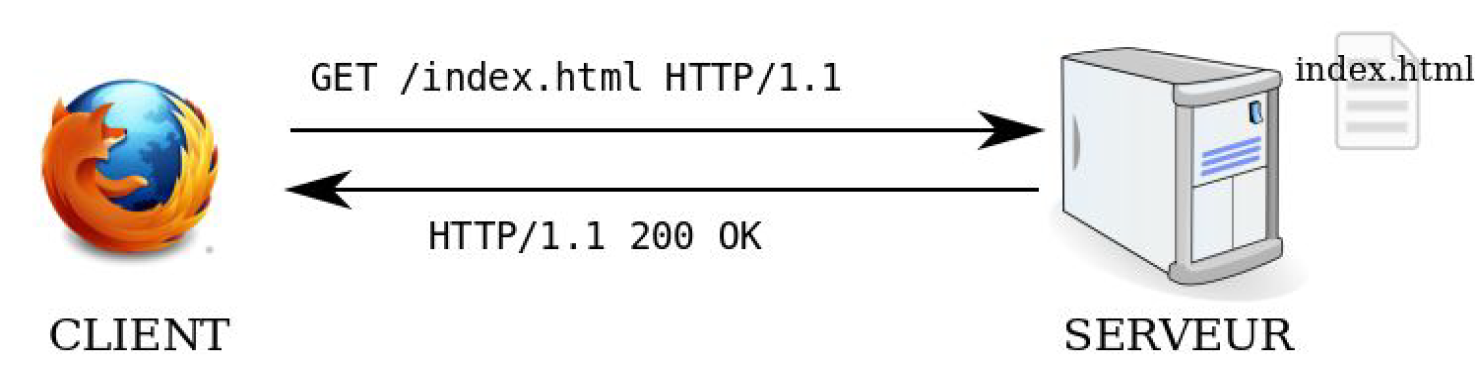
Quand un navigateur cherche à accéder à une page web située sur un autre ordinateur (serveur web),
il utilise DNS pour trouver l’adresse IP de l’ordinateur hôte sur lequel cette page web est hébergée ;
puis établit une connexion TCP sur le port 80 de la machine serveur ;
utilise ensuite le protocole HTTP pour demander cette page à l’ordinateur hôte (on dit qu'il effectue une requête).
le serveur envoie la page demandée via le protocole HTTP (le serveur répond) ;
la connexion TCP est terminée ;
le navigateur affiche la page.
Si le fichier n'existe pas ou que le traitement est impossible, le serveur web renvoie un message d'erreur au navigateur. Le message d'erreur le plus fréquemment rencontré est 404 Page non trouvée.
Formulaire d'une page Web
1. Définition
Un formulaire Web est un instrument qui permet l'interaction avec les utilisateurs (communiquer des informations, faire des choix et d'envoyer le tout au propriétaire de la page, qui peut être situé à l'autre bout du monde.)
Faites-vous plaisir :
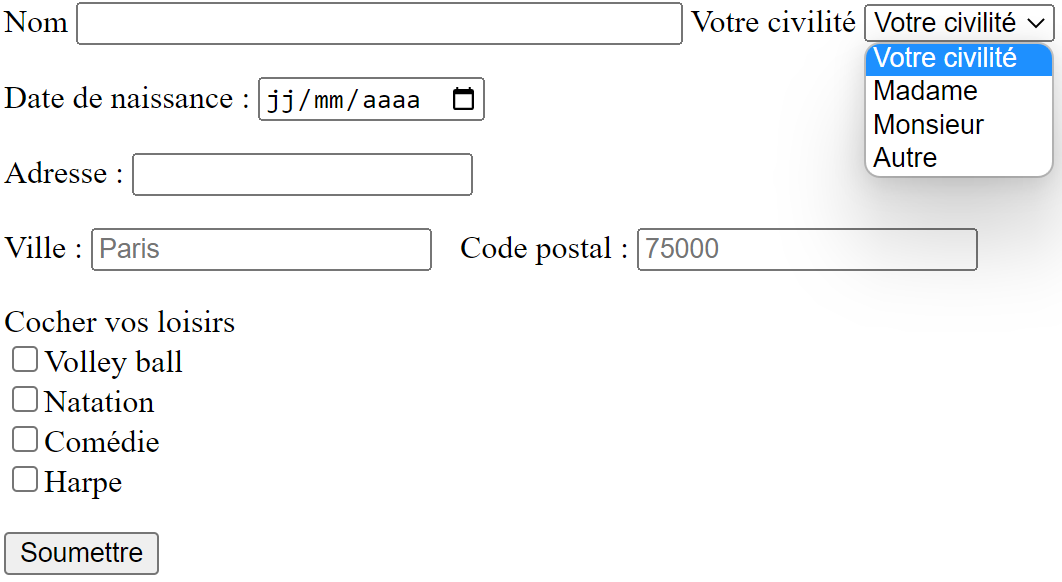
Créer et rendre joli le formulaire ci-après :
Pour la suite, créer le formulaire suivant :
L'ouvrir dans un navigateur.
Compléter le formulaire avec les données suivantes :
Nom : Durand
Email : durand@monserveur.fr
Message : Hello World !
Soumettre ces informations.
2. Analyse de l'interaction client-serveur
2.1. Côté client : Envoyer des données de formulaire à un serveur Web
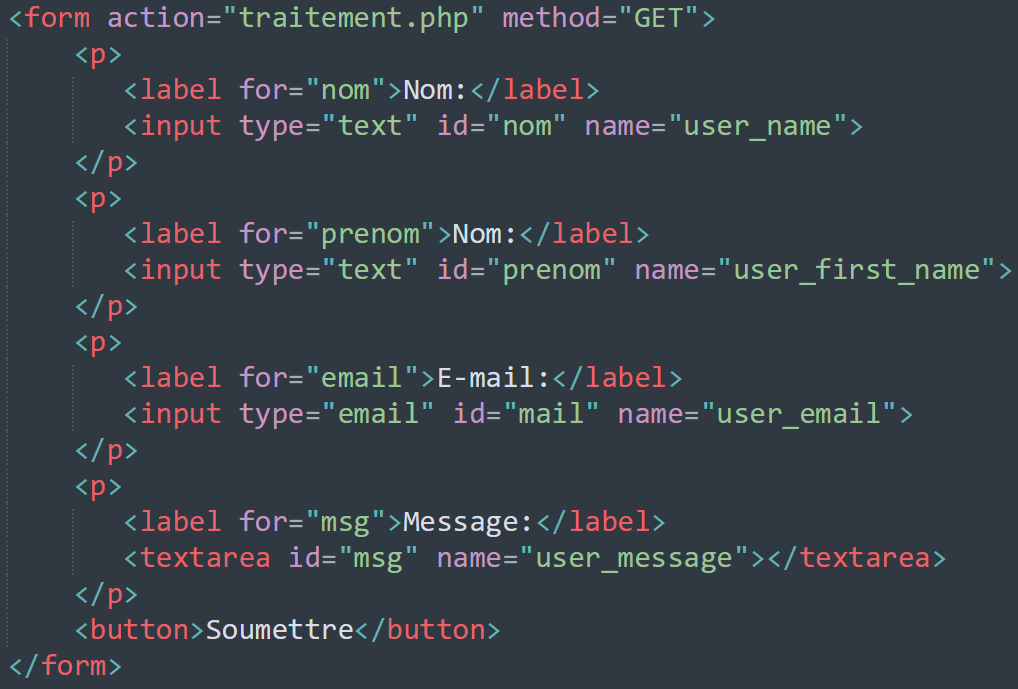
Chaque champ du formulaire doit être nommé grâce à l’attribut name de la balise form. Autrement dit, chaque champ doit être désigné par une variable.
L'attribut action cible où les données doivent être envoyées. Sa valeur doit être une URL valide.
L'attribut method définit la méthode HTTP à utiliser lors de l'envoi des données du formulaire.
Le protocole HTTP offre plusieurs façons d'effectuer une requête. Les données de formulaire HTML peuvent être transmises via un certain nombre de méthodes différentes, les plus courantes étant la méthode GET et la méthode POST.
Les données du formulaire sont envoyées au serveur sous forme de paires name/valeur.
Dans notre exemple, le formulaire enverra à l'URL "\traitement.php" 3 données nommées "user_name", "user_mail" et "user_message".
En utilisant la méthode HTTP-GET, lorsque l’utilisateur clique sur le bouton Soumettre, le navigateur rassemble les données collectées en une seule longue ligne et les transmet, via l'URL, au serveur à des fins de traitement.
On observe dans la barre d'adresse un URL qui ressemble à ce qui suit : /traitement.php?user_name=Durand&user_email=durand@monserveur.fr&user_message=Hello+World+!
2.2. Côté serveur : Récupérer des données d'un client Web
Le serveur reçoit une chaîne de caractères qui sera décomposée pour récupérer les données comme une liste de paires clé/valeur.
La façon d'accéder à cette liste dépend du langage utilisé.
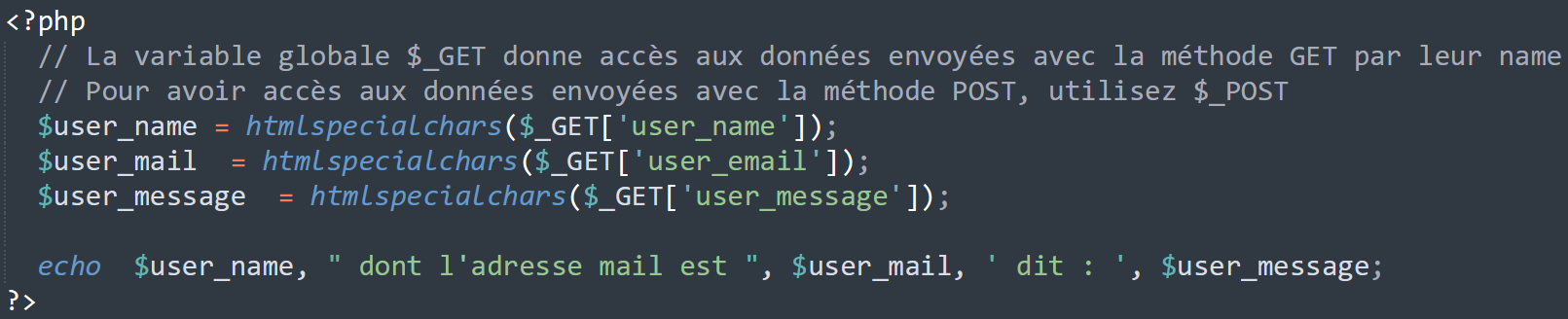
PHP met à disposition des variables dites globales pour accéder aux données.
Dans notre exemple, le script à l'URL "traitement.php" recevra les données sous la forme d'une liste de 3 éléments clé/valeur contenus dans la requête HTTP.
L'exemple suivant récupère les données et les affiche à l'utilisateur.
2.3. Protocole HTTP et HTTPS
L'attribut action de la balise form permet de cibler le fichier PHP qui va recevoir et traiter les informations transmises via le formulaire.
Le protocole de transfert utilisé pour la Toile (World Wide Web) est HTTP (HyperText Transfert Protocol). Il définit les messages que les clients peuvent envoyer au serveur, et ceux que le serveur peut transmettre en réponse.
Le protocole http définit un ensemble de méthodes de requête qui indiquent l’action que l’on souhaite réaliser sur la ressource indiquée.
2.3.1. La méthode GET
Avec la méthode GET, le transfert des données du formulaire (paramètres de l'URL) se fait en clair dans l'URL suivant le format ci-après : http://www.le-site-proprietaire.fr/un-dossier/traitement.php?var1=valeur1&var2=valeur2
Cette adresse signifie que, grâce au protocole HTTP, on transmet au fichier traitement.php, contenu dans le répertoire un-dossier du site le-site-proprietaire (à l'origine du formulaire) les couples variable/valeur passés en paramètre.
Les noms des variables correspondent aux valeurs des attributs name des éléments du formulaire et les valeurs aux données saisies.
Avantages de la méthode GET
Les paramètres d’URL peuvent être enregistrés avec l’adresse du site Web. Cela permet de marquer (« mettre dans les favoris ») une requête de recherche et de la récupérer ultérieurement. Si nécessaire, une page peut également être récupérée via l’historique de navigation. Inconvénients de la méthode GET
La principale limite de la méthode GET est le manque de protection des données. Les paramètres d’URL envoyés avec les données sont non seulement visibles par tout le monde dans la barre d’adresse du navigateur, mais sont également stockés non chiffrées dans l’historique du navigateur, la mémoire cache.
Par ailleurs, le nombre de caractères qui peuvent transiter par l’Url est limité.
Enfin, les paramètres d’URL ne peuvent contenir que des caractères ASCII, mais pas de données binaires telles que des fichiers audio ou des images.
2.3.2. La méthode POST
Contrairement à la méthode GET, les informations envoyées par le formulaire ne sont pas transmises via l’URL mais directement dans le corps de la requête http. Elles ne sont donc pas visibles par l'utilisateur. Avantages de la méthode POST
Lorsqu’il s’agit de transmettre des données sensibles au serveur - par exemple le formulaire d’inscription avec nom d’utilisateur et mot de passe - la méthode POST offre la confidentialité nécessaire. Les données ne sont ni mises en cache ni n’apparaissent dans l’historique de navigation. Un autre avantage est la flexibilité de la méthode POST. Les utilisateurs peuvent transmettre de courts textes, mais aussi des données de toute taille ou de tout type, telles que des photos ou des vidéos.
Attention ! les données sont certes masquées mais pas chiffrées. Inconvénients de la méthode POST
Si une page Web est mise à jour à l’aide du bouton « Précédent », par exemple, après avoir utilisé un formulaire Web, les données du formulaire doivent être soumises à nouveau.
De même, les données transmises à l’aide de la méthode POST ne peuvent pas être marquées avec l’URL. Quelle méthode privilégiée ?
Cela dépend.
Les informations transmises par la méthode GET de http peuvent facilement être copier-coller pour un autre usage. Mais on est limité dans le nombre de caractères qui peuvent transiter dans l’Url.
La méthode POST est préférée lorsqu'il y a un nombre important de données à transmettre ou bien lorsqu'il faut envoyer des données sensibles comme des mots de passe.
2.3.3. HTTPS (http sécurisé)
Pour rendre les requêtes HTTP sécurisées, dans la pile protocolaire du modèle OSI, on intercale une couche SSL (Secure Socket Layer) entre la couche transport et la couche application.
La couche SSL sert principalement à la compression et au chiffrement des données.
Au-dessus de cette couche, http sécurisé prend un s : HTTPS.
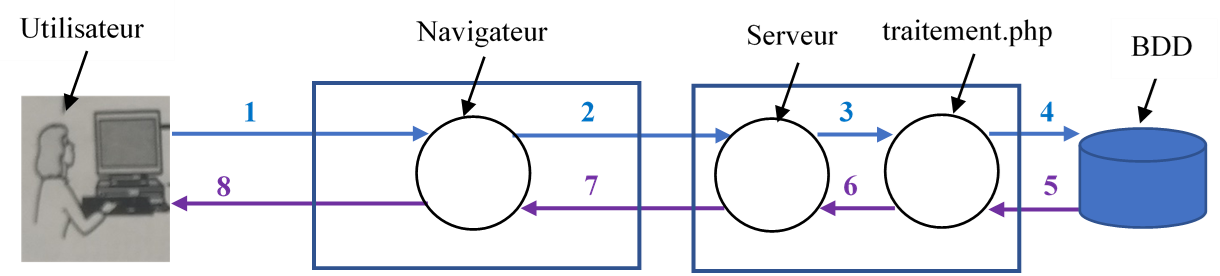
L'interaction client-serveur en bref :
Remplissage du formulaire
Formulaire retourné
Transfert au script du fichier traitement.php
Le script interroge la BDD
Enregistrement trouvé
Le script construit la page
Page retournée
Page affichée
2.4. Groupes de codes réponse
Pour finir, chaque requête http (du client) est suivie d’une réponse (du serveur) se composant d’une ligne d’état contenant un code d’état à trois chiffres qui indique si la requête a pu être satisfaite, et dans la négative, pour quelle raison.
Code
Signification
Exemples
1xx
Information
100 = Le serveur accepte de traiter la requête du client
2xx
Succès
200 = la requête a réussi ; 204 = contenu non présent
3xx
Redirection
301 = page déplacée ; 304 = page en cache
4xx
Erreur client
403 = page interdite ; 404 = page inexistante
5xx
Erreur serveur
500 = erreur interne ; 503 = requête à tenter plus tard